コラム
デジタル社会形成に向けて 第2章(19)~自治体DXの先に~
2023.11.28
訪問型行政サービスの効果測定を下記フローに沿って説明してきております。(下図記載)
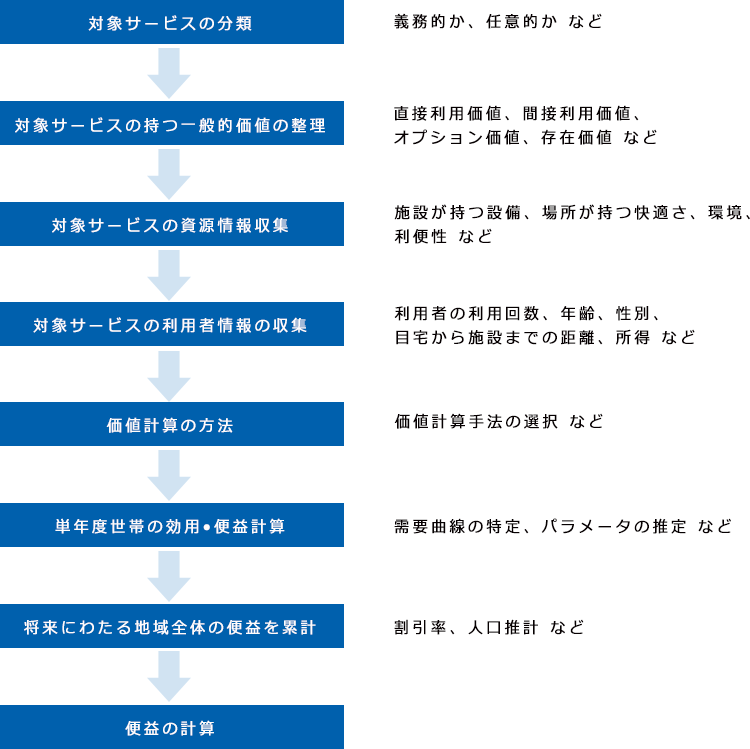 図1:訪問型行政サービスにおける効果測定フロー
図1:訪問型行政サービスにおける効果測定フロー
前回までのおさらい
これまでのコラムにおいて、ある行政サービスにおいて、選択結果が「0/1」のどちらかしかなく、右端と左端に偏った分布をしている場合について考えてみました。
最大の関心事は、それらの選択結果がどのような要因で決まり、その要因を推計する事は可能であるか?ということでした。そのような時、ロジスティック回帰と手法を用いることで、2つの選択肢に影響を与えている要因の「影響度」を推計できる事。また、係数の推計には「最尤法」を用いるという話をしてきました。
選択肢が複数ある場合
ここまで至れば、ある程度使い道のある分析手法を手に入れたと実感できると思いますが、更に深堀していくと、選択肢が2つではなく、3つ以上ある場合はどうするのだろうか?と考えたくなります。
実際、意思決定の際に、最終的には2つを並べて「どちらにするか」ということになるかもしれませんが、そこに辿り着くまでには、3つ以上の選択肢があるケースも多いでしょう。そこで今回は、3つ以上の選択肢がある場合について考えてみたいと思います。
多項モデル
これまで選択肢は2つ(二値)でしたが、選択肢が3つ以上出てくるので、「多項」と呼びます。(「多値」という言い方は用いられませんが…)これからは、手早く推計を行うため統計ソフト(RStudio)に最初から同梱されている’Fishing’ というデータセットを使わせていただきます。
なお、元となるデータは、ある年に南カリフォルニアに釣りをするために訪れた観光客について、どういった手段・場所で釣りを行ったのかについて、電話やアンケートで調査した結果を取り纏めた報告書が出所になっております。
データは、おおよそ下記の感じになっております。左端のmode:選択肢は4つあります。
① charter:ボートを借りて沖で釣り
② boat:自己所有のボートで釣り
③ pier:桟橋・埠頭で釣り
④ beach:浜辺で釣り
調査の対象となった人々が、どういう選択肢を採用したか?ということです。
 表1:Fishing(データセット)
表1:Fishing(データセット)
上記表1を確認すると、1行目の人は、ボートを借りて釣りをしていることが分かります。2列目price.beachから5列目price.charterまでは、それぞれの選択肢を採用した場合に要したコスト、6列目catch.beachから9列目catch.charterまでが、それぞれの「釣果率(その日、それぞれのmodeで何匹釣れたか)」を示しています。10列目incomeは各人の所得になります
各人は懐具合(所得)に制約を受けつつ、4種類のオプション(自己所有ボート・貸し切りボート・浜辺・埠頭)からどれかを選んで、釣りのパフォーマンスを上げる、という意思決定の問題になります。
さて、この問題を模式図的に書くと下記のように表すことができます。
「mode ← price |income | catch」
つまり、modeを決定づける変数(説明変数)として、まず個人にだけ依存している「income」と、個人とそれぞれの選択肢に依存している 「price」【price.beach, price.pier, price.boat, price.charter】、と「catch」【catch.beach, catch.pier, catch.boat, catch.charter】が存在することになります。
では、各項目がどの程度選択結果に影響を与えているのか?について推計してみましょう。実際には、それぞれの選択肢は「独立(※1)」など、吟味しなければならない難しい問題がありますが、突き詰めてしまうと本稿の守備範囲を超えますので、一旦、置いておきます。
このような推計を行うのに、さすがにExcelでは難しいため、各種統計ソフトが非常に助かります。今回も本コラムでよく用いている「RStudio」を用います。RStudioには’mlogit’というパッケージが含まれており、今回の多項ロジットや選択肢が「入れ子」になっているネスティッド・ロジット(※2)といった複雑な分析もできます。
今回の場合、RStudio では、以下のような形で実行します。
「mlogit(mode ~ price | income | catch, fish)」
最後にある’fish’というのは、今回推計に使ったデータセットを示しています。先に、一部をお見せしましたが、パッケージが要求するフォーマットに変形すると、以下のように表示されます。
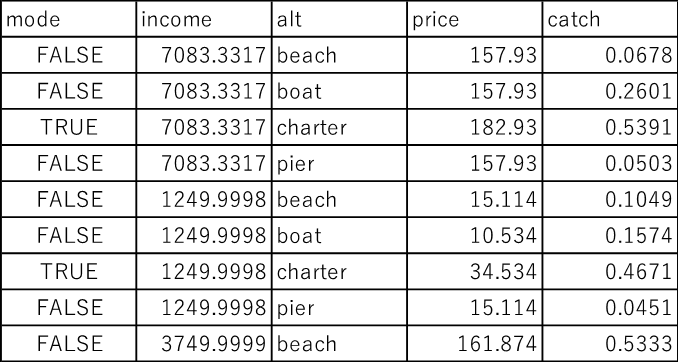 表2:fish(データセット)
表2:fish(データセット)
先程ご覧いただいた表1:Fishing(データセット)は、’Wide’というデータの持ち方になります。表2:fish(データセット)は、’long’と言われるデータの持ち方になっております。
贅言ながら、R言語で動く殆どの統計パッケージは、この’long’のデータフォーマットにて、データを要求するハズです。そのため、RStudioを用いて、様々な分析を行いたい分析者は、自由奔放な?データフォーマットを有するアンケートや各種データソースから、long型に「整理整頓」する作業が必要になります。そして、その作業を如何に効率的に行うかにによって、分析作業全体の生産性に大きな差が生じることになります。
推計結果
上記のコマンドを実行すると、下記のような、慣れないと難解な出力結果が表示されます。
 表3:回答結果
表3:回答結果
Sig. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Log-Likelihood: -1199.1
McFadden R^2: 0.19936
Likelihood ratio test : chisq = 597.16 (p.value = < 2.22e-16)
取り敢えず、上表1列目が、推計された変数の名称です。Incomeとcatchについては、それぞれ、beachとの対比として推計されています。すなわち、beachを基準として、それとの対比で、それ以外の選択肢が選ばれる確率を推計する、という仕組みになっております。
ここでの関心事は、「beach:boat:charter:pier」 の4つを選ぶに際して、「price:income:catch」の3つの要因が、それぞれどんな感じで作用するか?を探ることでした。そこを念頭に置きながら、次回、上表の読み方についてご説明したいと思います。
(以上)
コラムニスト
公共事業本部 ソリューションストラテジスト 松村 俊英
参考
- ※12つの事象について、一方の事象が変化したときにもう一方の事象が変化せず、それが相互に言える場合、この2つの事象は独立であると言う。独立でない場合は、連関がある、または関連があると言う。
https://bellcurve.jp/statistics/glossary/1402.html - ※2ロジットモデルにおいては、選択肢すべての効用は独立しており、その分散は等しいと仮定しているが、行動変化の予測が非現実的となるケースが考えられるため、効用の分散の大小を表現する係数を導入したモデル。(英:nested logit model)
http://glossary.jste.or.jp/
関連コラム
- デジタル社会形成に向けて 第2章(1)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(2)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(3)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(4)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(5)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(6)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(7)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(8)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(9)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(10)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(11)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(12)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(13)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(14)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(15)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(16)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(17)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(18)~自治体DXの先に~
- 「データ分析を考える」コラム一覧に戻る