コラム
デジタル社会形成に向けて 第2章(6)~自治体DXの先に~
2022.06.06
前回からの続き
訪問型の行政サービスの効果測定を下記フローに沿って説明してきております。(下図記載)
ある訪問型行政サービス(A公園の訪問価値)について、サンプルデータ、すなわち、公園利用者に関する訪問回数と訪問費用の関係データから、この公園サービスが持つ「価値=便益」の計測について話しを進めております。
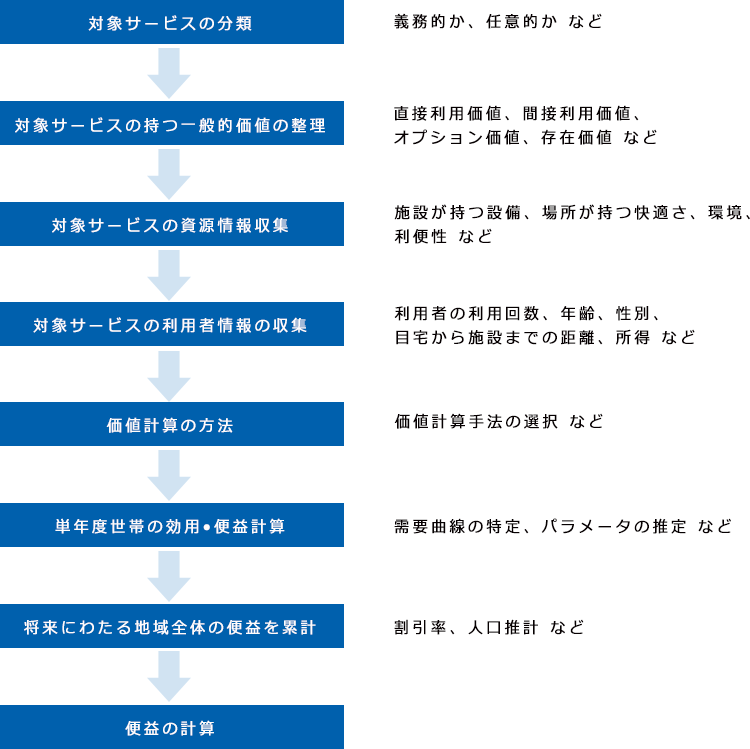 図:訪問型行政サービスにおける効果測定フロー
図:訪問型行政サービスにおける効果測定フロー
直線で近似する
「訪問型行政サービスは、利用者が訪問に掛けるコストを計算出来れば、コストの対価が、そのサービスの価値である。」と見なす事が出来るため、訪問費用と訪問回数の関係が分かれば、経済学でいうところの「需要曲線」が導き出され、近似的に便益を計算する事が可能になります。そして「需要曲線」をどのように特定すれば良いか?という問題を解決するために、得られた観測データのセットから、関係を導き出すところまで話を進めてきました。
今回の事例では、訪問回数と訪問費用について、6組のデータセットを有し、これら2つの関係については、ある種の仮説を持っていました。即ち「自宅からの距離が遠くて、訪問費用が掛かる人は、訪問回数が少ないだろう」という読みです。そこで、散布図を作ってみると、やはり比例的な関係が有りそうだということで、それっぽい直線を引いてみることにしました。
とは申せ、闇雲に直線を引くわけにはいかないので、「最小二乗法」という考え方を用いて、数多ある直線の中から一本を選ぶことにしました。この考え方に基づき、残差平方和が最小になるような線を選択すること、つまり、今回入手した2つのデータ間には、明確な関係があると思うが、何かの事情で、若干データがバラついているように見える。そこで、バラツキを「矯正」して、すっきりとした直線で表現しておこう、としたのです。
この例の場合、勝手に「比例=直線関係」と決めつけておりますが、真の関係は曲線で表現されるものなのかも知れません。とはいえ、曲線より直線の方が表現、あるいは取扱をする上でも容易であるため、直線で関係を表現させていただきます。
サンプルサイズの問題
続いて、データのサイズの話しです。今回は、6組のデータセットを元に比例式を推計したのですが、そのデータセットが2組しか無かったら、あるいは、600組有ったら話はどうなるでしょうか?実際には、意思決定の現場において、分析のためのデータセットが2組という事はほぼ皆無であり、アンケートを収集した場合ならば、より多くのデータセットが集まるでしょう。
それでも、2組しかデータセットが無い場合でも、直線は定義できます。ただ、「たまたま」手に入れた2組のデータセットから、何らかの関係を予測するのは、リスクが非常に大きいです。手に入れたデータに「偏り」が有るかもしれません。
他方で、600組のデータセットが有れば十分か?実際にA公園を訪れた人が600人しかおらず、その全数をデータとして取得できているのあれば問題ありません。但し、実際には600,000人がA公園を訪れており、その中からサンプルとして600件だけデータを取得したのであれば、これは微妙な感じになります。結局、分析対象とする事柄について、全てを取得したのか、部分的なサンプルを取得したのかで、話が変わってくるということになります。
政策決定の現場において「漏れなく全て」をデータとして取得できるケースはごく稀でしょう。技術的には可能であっても、コストが掛かり過ぎてしまいます。結果として、サンプルデータを取得して、それらの性質から、見ることのできない元の集団の性質を想像することになります。元の集団を「母集団」、サンプルのことを「標本」と呼んだりするのは、ご存じの方も多いでしょう。
では、本当の母集団のサイズに対して、サンプルのサイズはどれ位であれば「良し」とされるのか?その議論は、本コラムの範疇を超えてしまいますが、情報を収集してみると、様々な計算式が紹介されております。
例えば、工場の抜き取り検査などでは、サンプルサイズの決定がクリティカルな問題になるかと思います。全数を調査してしまうと、確かに不良品を出荷するリスクは無くなるでしょうが、出荷できる製品が無くなってしまいます。一例としてJIS規格において、ロット数に対する必要なサンプルサイズなどが明示されており、ロットサイズが501〜1,200の場合ですと、80個を抜き出せば良いそうです。(※1)
サンプルの特徴
行政サービスの価値=便益を計算する際にも、サンプリング調査をした上で、その背後に存在する「母集団」の特性を推計することになります。そのためにデータを集めることになるのですが、次に気になるのが、集まった個々のデータの特徴です。例えば、既出6組のA公園利用データについては、性別とか職業といった利用者の属性や、公園設備の良し悪しは考慮されておりません。
DXが進むことで、より多くのサンプルデータを容易に収集出来るようになると思うのですが、今後は、その内訳をうまく利用したいのです。仮に、「男性の公園利用を促す」といった政策目標が立てられた場合、男性をターゲットにして、「どの様な条件が揃えば公園を利用するか」というアンケートを取るのもアリでしょうし、実際に公園を利用している男性の属性を分析するのもアリでしょう。そうなると、次に、男性といっても大雑把なので、もう少し細かく、例えば、年齢などの要素を入れて…、と話が展開していく事が可能になります。
次回、この先の展開についてもう少し続けます。
(以上)
コラムニスト
公共事業本部 ソリューションストラテジスト 松村 俊英
参考
- ※1サンプリングに関するガイドライン(厚生労働省HP)
https://www.mhlw.go.jp/topics/idenshi/codex/06/dl/cac_gl50.pdf
関連コラム
- デジタル社会形成に向けて 第2章(1)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(2)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(3)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(4)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(5)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(6)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(7)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(8)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(9)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(10)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(11)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(12)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(13)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(14)~自治体DXの先に~
- デジタル社会形成に向けて 第2章(15)~自治体DXの先に~
- 「データ分析を考える」コラム一覧に戻る